AI Brand Monitoring Tools for Enterprises: What C-Suite Leaders Need to Know in 2026
Last updated: December 2026 | Reading time: 18 minutes
As AI chatbots process billions of queries monthly, enterprise brands face a new challenge: understanding and optimizing their visibility in AI-generated responses. But selecting the right monitoring platform requires evaluating factors that most vendor marketing ignores.
This guide focuses on three critical enterprise requirements that separate decision-grade platforms from unreliable data sources:
- Data Reliability - Why single-query sampling gives you ±43% error, and what accuracy level you actually need
- ROI Calculation - How AI SEO scores and difficulty metrics enable real prioritization
- Executive Reporting - Clear status tracking and improvement measurement for stakeholder communication
Comprehensive landscape of enterprise-grade AI brand monitoring platforms with multi-query reliability and executive reporting capabilities
See your AI SEO Score, Brand Rank, and ROI opportunity analysis across all major LLMs
No credit card required • All major LLMs • 10-query reliability
Why Data Reliability Is Non-Negotiable for Enterprise Decisions
Here's what most AI brand monitoring vendors don't tell you: LLM responses vary significantly between queries. Ask ChatGPT the same question 10 times and you'll often get different brand recommendations. This variability has massive implications for data accuracy.
The Reliability Problem
Most platforms use single-query sampling - they ask each prompt once and report that result as truth. The problem? Single-query sampling has ±43 percentage points of potential error.
What this means in practice: A brand showing 24% visibility in a single-query platform could actually have anywhere from 0% to 67% real visibility. You cannot make reliable business decisions with this margin of error.
Enterprise-Grade Reliability Standards
For decision-grade data, enterprises need platforms that run multiple queries per prompt:
- Single-query (1x): ±43% error - unsuitable for business decisions
- 3-query sampling: Better, but still high error margin
- 8-query sampling: Approaching acceptable accuracy
- 10-query sampling (3x more accurate): Error reduces to ±14% - reliable enough for strategic decisions
- 100-query sampling (10x more accurate): Scientific-level accuracy at ±4%
Key insight: A platform offering 2,500 prompts with single-query sampling provides less reliable data than one offering 250 prompts with 10-query verification. Volume without reliability is just noise.
Reliability by Platform
Decision-grade AI brand tracking with multi-query verification reducing error margins from ±43% to ±14%
Based on our research, here's how major platforms handle query sampling:
- Sellm: 10 queries per prompt (3x more accurate than single-query)
- Profound: 8 queries per prompt
- Peec AI: 3 queries per prompt
- AthenaHQ: 1 query per prompt (±43% error)
- Otterly AI, Scrunch AI, Semrush: Not disclosed
ROI Strategy: Using AI Difficulty and Volume to Prioritize
Enterprise marketing teams can't optimize for every keyword. You need a framework to prioritize efforts based on potential return. This requires two metrics most platforms don't provide:
1. AI SEO Score (Difficulty Assessment)
The AI SEO Score evaluates how difficult it is to rank for a specific prompt in AI responses.
In traditional SEO, keyword difficulty scores range from 0-100, where a score of 70+ typically means you need significant domain authority and backlinks to compete - roughly only 5-10% of websites can realistically rank for those terms. AI SEO works the same way. Some prompts are dominated by established brands with deep content libraries, while others represent open opportunities where a well-optimized page can capture visibility quickly.
The Two-Step Process: Retrieval and Citation
Just like traditional SEO has two distinct phases - indexing (getting into Google's database) and ranking (appearing in top results) - AI SEO has an analogous two-step process:
Step 1: Retrieval - Getting into the LLM's consideration set
Before an AI can recommend your brand, it must first retrieve your content as a potential source. This is similar to Google indexing your pages. Factors that influence retrieval include:
- Whether your content exists in the LLM's training data or can be accessed via web search
- Content freshness and update frequency
- Domain authority signals that make your site a trusted source
- Structured data that helps LLMs understand your content's relevance
Step 2: Citation - Actually being mentioned in the response
Once retrieved, your content competes with other sources for the actual citation. This is where AI SEO difficulty becomes critical. Just because an LLM "knows about" your brand doesn't mean it will recommend you. Citation depends on:
- Content-Answer Fit (55%): How well does your content directly answer what the user is asking? LLMs favor content that provides complete, relevant answers.
- On-Page Structure (14%): Is your content structured in ways LLMs can easily parse and quote? Clear headings, lists, and direct statements perform better.
- Domain Authority (12%): How trusted is your domain? LLMs weight authoritative sources more heavily.
- Competitive Density: How many strong competitors are already dominating this prompt? Some queries have 5+ established brands competing for mentions.
Why this matters for ROI: Without understanding both retrieval and citation difficulty, teams waste resources. You might optimize content that gets retrieved but never cited (high retrieval, low citation probability), or target prompts where you're not even in the consideration set (low retrieval, making citation impossible).
Platforms that only show "visibility" don't distinguish between these steps. You need AI SEO scoring that evaluates both retrieval likelihood and citation difficulty to prioritize effectively.
2. Volume and Value Estimation
Not all prompts have equal business value. Some platforms show search volume, but few connect this to actual ROI potential. The calculation requires:
- Prompt Volume: How often is this query asked across AI platforms?
- Conversion Potential: What's the purchase intent behind this query?
- Current Share of Voice: What percentage of responses currently mention your brand?
- Difficulty Score: What's the realistic chance of improvement?
ROI Prioritization Framework
Combining these metrics creates a prioritization matrix:
- High Volume + Low Difficulty + High Intent = Priority 1 - Maximum ROI potential
- High Volume + High Difficulty = Priority 2 - Worth the investment if competitive
- Low Volume + Low Difficulty = Priority 3 - Quick wins, limited impact
- Low Volume + High Difficulty = Deprioritize - Poor ROI potential
Platform Capabilities for ROI Analysis
- Sellm: AI SEO Score + difficulty assessment + volume data + actionable prioritization
- AthenaHQ, Profound: Partial volume data (total mentions, not difficulty)
- Otterly AI, Peec AI, Scrunch AI: No ROI per keyword analysis
Executive Reporting: Clear Status and Improvement Tracking
Enterprise stakeholders need clear, defensible metrics - not raw data dumps. Effective AI brand monitoring requires reporting frameworks that answer three questions:
1. Current Status - "Where are we now?"
Executives need clear visibility metrics that translate to business impact:
- Share of Voice: What percentage of AI responses in your category mention your brand vs. competitors?
- Brand Rank: When your brand is mentioned, what position does it hold (1st, 2nd, 3rd recommendation)?
- Coverage by Platform: Are you visible on ChatGPT but invisible on Claude or Perplexity?
- Sentiment Distribution: Are mentions positive, neutral, or negative?
2. Trend Analysis - "Are we improving?"
Historical tracking is essential for measuring the impact of optimization efforts:
- Week-over-Week Change: How has visibility changed since last reporting period?
- Campaign Attribution: Did specific content or PR initiatives move the needle?
- Competitive Movement: Are competitors gaining or losing ground?
- Seasonal Patterns: Are there predictable visibility fluctuations?
3. Action Plan - "What should we do next?"
The most valuable platforms don't just report data - they provide specific recommendations:
- Actionable Lists: Specific content changes, structural improvements, or authority-building tactics
- Priority Ranking: Which actions will have the highest impact for the lowest effort?
- Exact Chat Examples: Actual AI responses showing how competitors are positioned
Reporting Capabilities by Platform
- Sellm: Full reporting suite - Share of Voice, Brand Rank, historical trends, actionable lists, exact chat viewing
- Otterly AI: Share of Voice, Brand Rank, some historical data, actionable items
- AthenaHQ: Share of Voice, sentiment, but limited actionable guidance
- Profound: Brand Rank, historical tracking, but no actionable lists or sentiment
- Scrunch AI: Share of Voice, citations, but no AI SEO scoring or recommendations
Platform Deep Dives
Sellm - Enterprise-Grade Reliability with ROI Framework
Pricing: $89/month (Basic), $199/month (Pro), Enterprise custom
Sellm is built around the three enterprise requirements outlined above. Its 10-query reliability provides decision-grade accuracy, while the AI SEO Score enables genuine ROI prioritization. The platform covers all major LLMs including ChatGPT, Claude, Perplexity, Gemini, Grok, and Google AI Overviews.
Strengths:
- 10-query verification (3x more accurate than single-query)
- AI SEO Score with difficulty assessment
- ROI per keyword prioritization
- Actionable improvement lists
- Exact chat viewing for verification
- Complete LLM coverage including Grok
- Free initial audit
Considerations:
- Newer platform compared to traditional social listening tools
- Focused on AI channels, not traditional social media
Otterly AI - Budget-Friendly with Good Coverage
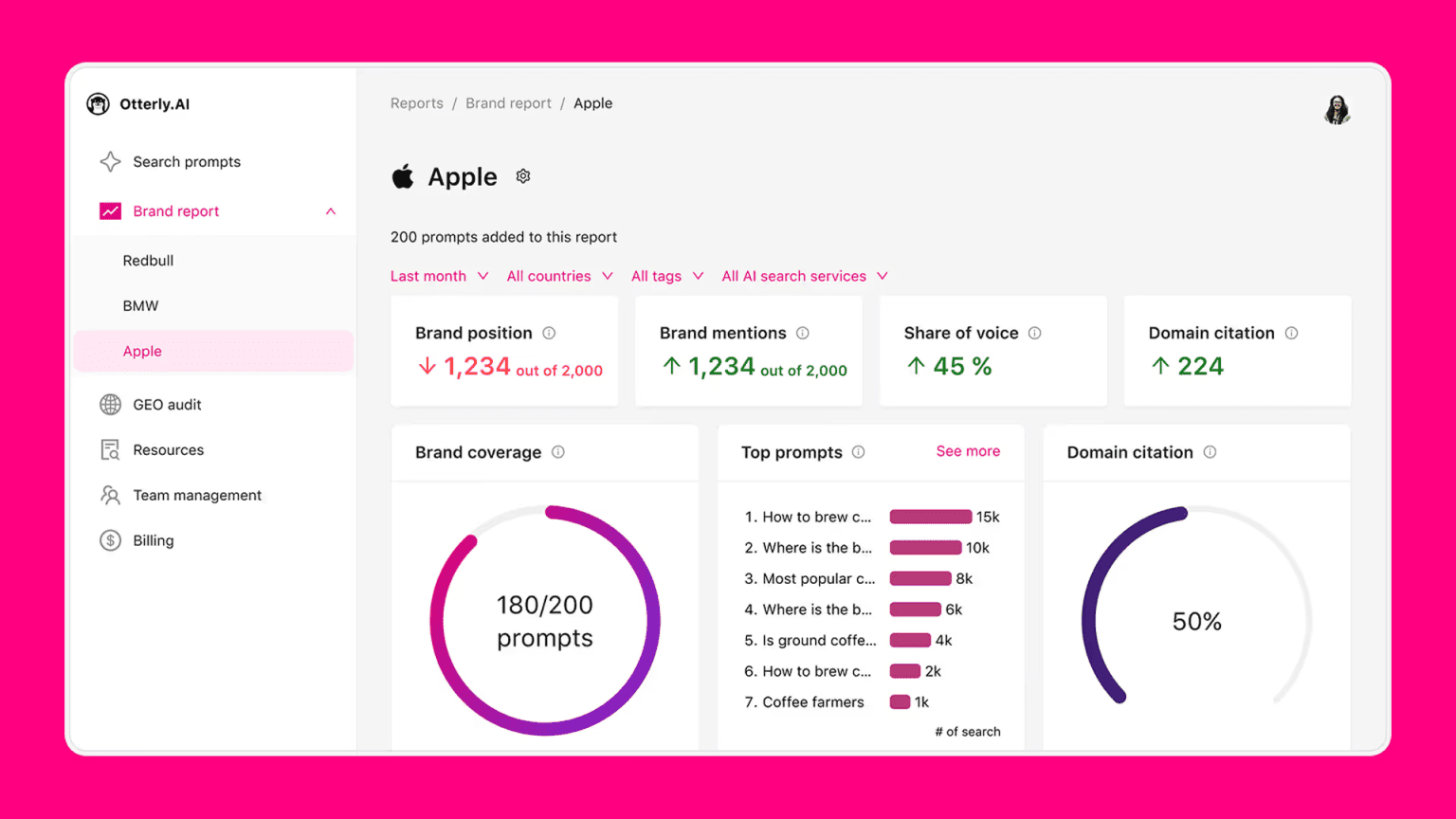
Affordable AI brand monitoring platform with multiple geography support and sentiment analysis for SMB and enterprise teams
Pricing: $29/month (Starter), $189/month (Pro)
Otterly AI offers competitive pricing for teams with limited budgets. It provides solid feature coverage including historical tracking, multiple geography support, and sentiment analysis. However, reliability metrics aren't disclosed, and it lacks AI SEO scoring.
Strengths:
- Affordable entry at $29/month
- Historical tracking and trend analysis
- Multiple geography support
- Sentiment analysis
- Citations tracking
- Free trial available
Limitations:
- Missing Grok coverage
- No AI SEO Score for ROI prioritization
- Unknown reliability (query sampling not disclosed)
- Weekly updates only
AthenaHQ - Comprehensive LLMs, Low Reliability
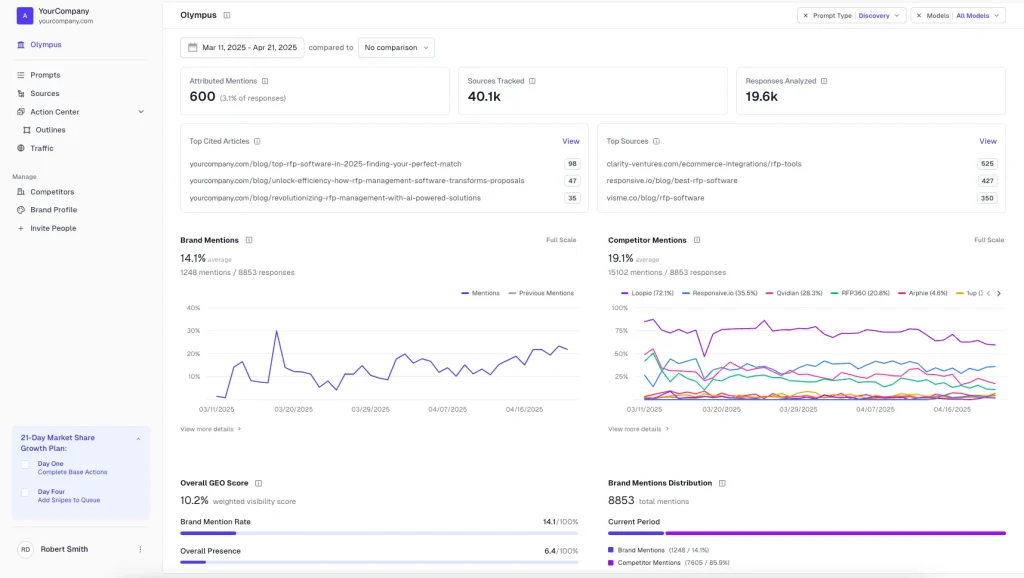
Multi-platform Generative Engine Optimization monitoring across all major LLMs with sentiment tracking capabilities
Pricing: $295/month (Standard), Enterprise custom
AthenaHQ offers coverage across all major LLMs, but at $295/month with single-query reliability (±43% error), the value proposition is questionable for strategic decision-making.
Strengths:
- All major LLMs covered
- Historical tracking
- Sentiment analysis
- Enterprise plans available
Limitations:
- Single-query reliability (±43% error)
- High price for low accuracy
- No free trial
- No AI SEO Score
- Full geography only on enterprise
Profound - Better Reliability, Limited Features
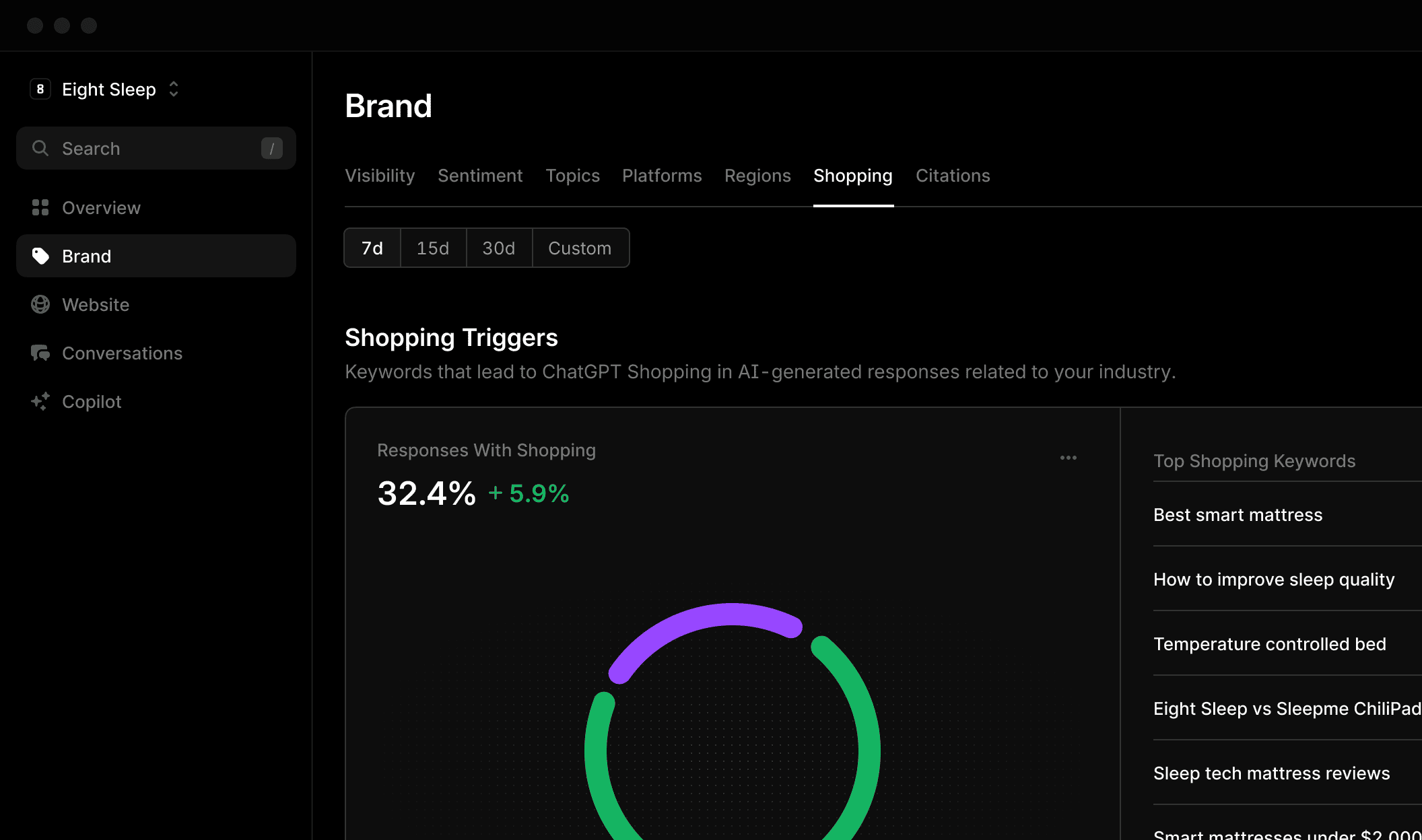
Reliable AI brand monitoring with 8-query verification, daily updates and brand rank competitive analysis
Pricing: $99/month (Starter), $399/month (Growth)
Profound uses 8-query sampling, making it more reliable than single-query platforms. However, it lacks AI SEO scoring, actionable lists, and sentiment analysis - limiting its strategic value.
Strengths:
- 8-query reliability (better than most)
- Daily updates
- Brand rank tracking
- Free trial available
Limitations:
- Limited LLM coverage (ChatGPT only on starter)
- No AI SEO Score
- No actionable lists
- No sentiment analysis
- High price for Growth tier ($399)
Peec AI - Daily Updates, Limited Coverage
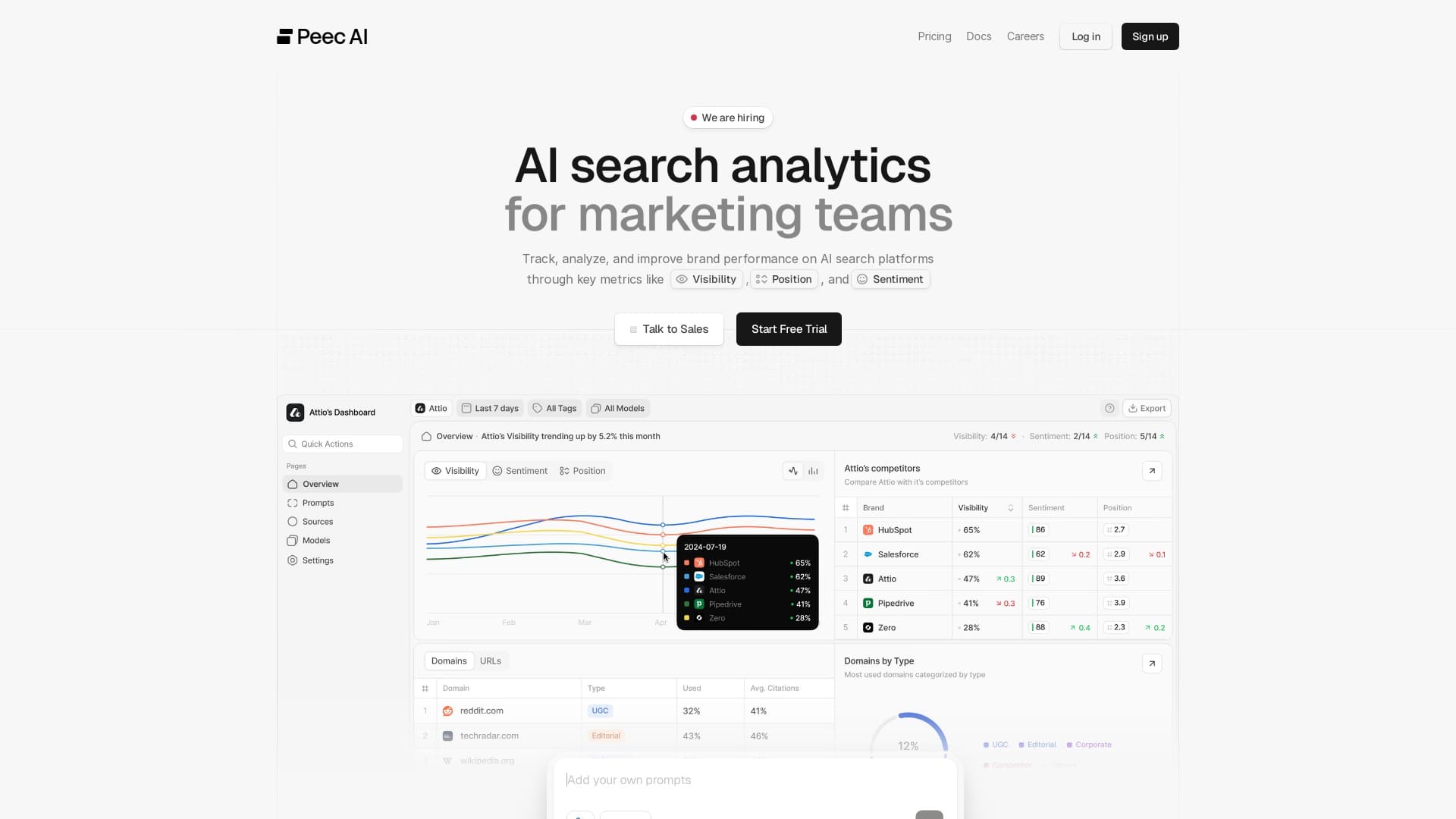
Daily AI brand monitoring platform with 3-query sampling, multiple geography support and sentiment tracking
Pricing: $89/month (Starter), $199/month (Pro)
Peec AI offers daily monitoring frequency but with only 3-query reliability and missing coverage for Grok and Copilot.
Strengths:
- Daily update frequency
- Multiple geography support
- Sentiment analysis
Limitations:
- 3-query reliability (still significant error)
- Missing Grok and Copilot
- No AI SEO Score
- No free trial
Scrunch AI - High Volume, Unknown Reliability
Premium high-volume AI monitoring platform offering 350-700 prompts with broad LLM coverage for enterprises
Pricing: $300/month (Starter), $500/month (Pro)
Scrunch AI offers the highest prompt volumes (350-700) but at premium pricing with undisclosed reliability metrics.
Strengths:
- High prompt volume
- Broad LLM coverage
- Free trial available
Limitations:
- Premium pricing ($300-500/month)
- Unknown reliability
- No AI SEO Score
- Missing Copilot
Semrush AI Toolkit - For Existing Users Only
AI tracking add-on for Semrush users combining traditional SEO and AI brand monitoring in familiar interface
Pricing: Requires Semrush subscription ($99+/month)
Semrush added AI tracking as an add-on, convenient for existing users but not available standalone.
Goodie AI - Not Yet Available
Currently in closed beta with no public access or confirmed pricing.
Enterprise Selection Framework
For Maximum ROI Visibility and Strategic Planning
Choose Sellm ($89-199/month) if you need reliable data (10-query), AI SEO scoring for ROI prioritization, and actionable improvement recommendations. Best for teams that need to justify AI visibility investments to stakeholders.
For Budget-Conscious Teams
Choose Otterly AI ($29-189/month) if budget is the primary constraint and you can accept unknown reliability metrics and missing Grok coverage.
For Reliability Without Advanced Features
Choose Profound ($99-399/month) if data reliability is your priority but you don't need AI SEO scoring or ROI frameworks.
Ready for Enterprise-Grade AI Brand Monitoring?
Get your AI SEO Score, ROI prioritization, and actionable recommendations with 10-query reliability
Start Free Enterprise Audit →No credit card required • All major LLMs • Decision-grade accuracy
Frequently Asked Questions
What level of data reliability do enterprises need for AI brand monitoring?
For strategic decision-making, enterprises need platforms with at least 8-10 query verification per prompt. Single-query sampling (used by many platforms) has ±43% error margins - unsuitable for business decisions. 10-query platforms reduce error to approximately ±14%, which is reliable enough for budget allocation and optimization decisions.
How do you calculate ROI for AI brand visibility investments?
Effective ROI calculation requires combining AI SEO difficulty scores with volume data. Platforms like Sellm provide AI difficulty assessment alongside volume metrics, enabling prioritization by ROI potential. High-volume, low-difficulty prompts with strong purchase intent offer the highest returns.
What reporting metrics do C-suite executives need?
Executives need clear status metrics (Share of Voice, Brand Rank by platform), trend analysis (week-over-week changes, competitive movement), and action plans (prioritized recommendations with expected impact). The best platforms provide all three with historical tracking.
Why don't all platforms disclose their query sampling method?
Transparency around reliability metrics can reveal competitive disadvantages. Platforms using single-query sampling (with ±43% error) may avoid disclosure because the accuracy limitations are significant. Always ask vendors directly about their sampling methodology before committing.
Which AI brand monitoring tool is best for enterprises?
For enterprise requirements (reliability, ROI framework, executive reporting), Sellm offers the most complete solution at $89-199/month with 10-query reliability and AI SEO scoring. Profound provides good reliability at $99-399 but lacks strategic features. Budget-conscious teams may start with Otterly AI at $29/month, accepting feature and reliability limitations.
Ready to implement enterprise-grade AI brand monitoring? Sellm offers 10-query reliability, AI SEO scoring for ROI prioritization, and actionable reporting frameworks. Start your free enterprise audit today.